Statistical Significance | Effect Estimation | Clinical Interpretation
Interpreting Results
Critical Must-Knows
- P-Value: Probability of observing data as extreme as yours IF null hypothesis is true. NOT probability that null is true.
- Confidence Interval (95% CI): Range of plausible values for true effect. If repeated many times, 95% of CIs would contain true value.
- Statistical Significance (p less than 0.05): Does NOT equal clinical importance. Must compare effect to MCID.
- CI Interpretation: If 95% CI excludes null (0 for difference, 1 for ratio), result is statistically significant at p less than 0.05.
- CI Width: Narrow CI = precise estimate. Wide CI = imprecise, underpowered study.
Clinical Pearls
- "p = 0.05 is arbitrary threshold - not magic cutoff between real and unreal
- "p-value depends on sample size - large studies find significance in trivial differences
- "CI provides effect size AND significance - more informative than p-value alone
- "CI that crosses MCID suggests effect may not be clinically meaningful
Critical Interpretation Concepts
What P-Value Is NOT
Common Misconceptions: p-value is NOT (1) probability null is true, (2) probability of Type I error, (3) proof of effect size, or (4) measure of clinical importance.
What P-Value Actually Means
Correct Interpretation: p = 0.03 means if null hypothesis is true, there is 3% chance of observing data this extreme or more extreme by random chance alone.
CI Contains More Information
Advantage: CI shows effect size, direction, precision, and statistical significance. p-value only shows significance, not magnitude.
Statistical vs Clinical Significance
Critical Distinction: p less than 0.05 means statistically significant. Clinical significance requires effect to exceed MCID. Can have one without the other.
PENTP-Value Common Misinterpretations
| P | Probability null is true WRONG - p-value is probability of data given null is true, NOT probability null is true |
| E | Effect size WRONG - p-value does NOT tell you magnitude of effect, only significance |
| N | Number needed (power) WRONG - p-value does NOT indicate if study was adequately powered |
| T | Type I error for THIS study WRONG - p-value is NOT probability of Type I error (that is alpha = 0.05 before study) |
| P | Probability null is true WRONG - p-value is probability of data given null is true, NOT probability null is true | N | Number needed (power) WRONG - p-value does NOT indicate if study was adequately powered |
| E | Effect size WRONG - p-value does NOT tell you magnitude of effect, only significance | T | Type I error for THIS study WRONG - p-value is NOT probability of Type I error (that is alpha = 0.05 before study) |
Hook:Do not get PENT up in p-value misinterpretations - these are what p-value is NOT!
REPSConfidence Interval Interpretation
| R | Range of plausible values CI provides range where true effect likely lies |
| E | Effect size estimate Point estimate (mean/median) is best guess of true effect |
| P | Precision Narrow CI = precise, wide CI = imprecise |
| S | Statistical significance If CI excludes null, result is statistically significant |
| R | Range of plausible values CI provides range where true effect likely lies | P | Precision Narrow CI = precise, wide CI = imprecise |
| E | Effect size estimate Point estimate (mean/median) is best guess of true effect | S | Statistical significance If CI excludes null, result is statistically significant |
Hook:Get good REPS with confidence intervals - they build stronger inference than p-values alone!
Overview/Introduction
What Are P-Values and Confidence Intervals?
P-values and confidence intervals (CIs) are the two primary tools for statistical inference in orthopaedic research. They address different but complementary questions:
- P-value: Tests whether observed data are compatible with the null hypothesis (no effect/difference)
- Confidence interval: Estimates the range of plausible values for the true effect
Why This Matters: Misinterpretation of p-values is pervasive in medical literature. Understanding these concepts prevents overconfident claims from underpowered studies and helps distinguish statistically significant but clinically trivial findings from truly meaningful results.
Historical Context: Ronald Fisher introduced p-values in the 1920s as a continuous measure of evidence against the null hypothesis. The 0.05 threshold became convention, not scientific law. Jerzy Neyman and Egon Pearson later developed confidence intervals in the 1930s as a complementary approach to estimation.
Current Emphasis: Modern statistical guidelines (ASA 2016, CONSORT, STROBE) emphasize reporting effect sizes and confidence intervals over dichotomous p-value thresholds. Journals increasingly require CIs alongside or instead of p-values.
Clinical Relevance in Orthopaedics:
- Distinguishing statistical significance from clinical importance (MCID)
- Interpreting RCT results for treatment decisions
- Evaluating diagnostic test accuracy studies
- Assessing prognostic factor analyses
- Critical appraisal for exam vivas and clinical practice
Understanding p-values and CIs is essential for evidence-based orthopaedic practice and exam success.
Principles of Statistical Inference
Fundamental Definitions
P-Value (Probability Value):
- Definition: The probability of observing data as extreme as, or more extreme than, what was observed, assuming the null hypothesis is true
- Formula: p = P(Data | H₀ is true)
- NOT: p ≠ P(H₀ is true | Data) - this is the most common error
- Range: 0 to 1 (often expressed as 0 to 100%)
Confidence Interval (CI):
- Definition: A range of values that, if the study were repeated many times, would contain the true population parameter in 95% of studies (for 95% CI)
- Components: Point estimate (observed effect) ± margin of error
- Interpretation: Provides effect size, direction, precision, and significance simultaneously
- NOT: There is NOT a 95% probability the true value is in this specific CI (frequentist interpretation forbids this)
Null Hypothesis (H₀):
- Definition: Statement of no effect, no difference, or no association
- Examples:
- Mean difference = 0
- Risk ratio = 1
- Correlation coefficient = 0
Alternative Hypothesis (H₁):
- Definition: Statement that there IS an effect, difference, or association
- Can be: Two-sided (any difference) or one-sided (specific direction)
Relationship Between P-Values and Confidence Intervals
Key Connection: P-values and confidence intervals are mathematically related:
- For 95% CI: If the CI excludes the null value (0 for differences, 1 for ratios), then p less than 0.05
- For 99% CI: If the CI excludes the null value, then p less than 0.01
- For 90% CI: If the CI excludes the null value, then p less than 0.10
Why This Matters: You can determine statistical significance directly from the confidence interval without needing the p-value. This is why modern guidelines emphasize CIs over p-values - they provide MORE information (effect size, precision, AND significance).
Understanding P-Values
What is a P-Value?
Definition: The probability of observing data as extreme as, or more extreme than, the observed data, assuming the null hypothesis is true.
Null Hypothesis (H₀): There is no difference between groups or no effect.
Formula: p = P(Data | H₀ is true)
Interpreting P-Values
P-Value Interpretation
| p-value | Interpretation | Conclusion | Action |
|---|---|---|---|
| p less than 0.01 | Very strong evidence against null | Highly statistically significant | Check effect size and clinical relevance |
| p = 0.01 to 0.05 | Moderate evidence against null | Statistically significant | Check confidence interval and MCID |
| p = 0.05 to 0.10 | Weak evidence, borderline | Not statistically significant | Consider if underpowered, examine trend |
| p greater than 0.10 | Little evidence against null | Not statistically significant | Check power, may be true null or Type II error |
Key Point: p = 0.051 is NOT fundamentally different from p = 0.049. The 0.05 threshold is arbitrary convention, not natural boundary.
Common P-Value Misconceptions
What P-Value Does NOT Tell You
Misconception 1: p-value is the probability that the null hypothesis is true.
- WRONG: p assumes null is true, then calculates probability of data.
- Correct: p is P(Data | Null is true), NOT P(Null is true | Data).
Misconception 2: p-value is the probability of a Type I error.
- WRONG: Type I error rate is alpha (set before study, usually 0.05).
- Correct: p-value is calculated from observed data, alpha is pre-set threshold.
Misconception 3: p-value tells you the size of the effect.
- WRONG: p-value reflects both effect size AND sample size.
- Correct: Large sample can yield p less than 0.05 for trivial effects.
Misconception 4: p greater than 0.05 proves null hypothesis.
- WRONG: Failure to reject null does not prove null is true.
- Correct: May be underpowered (Type II error) or true null.
Understanding these misconceptions prevents misinterpretation.
Understanding Confidence Intervals
What is a Confidence Interval?
Definition: A range of values that likely contains the true population parameter.
95% CI Interpretation: If we repeated the study many times, 95% of the confidence intervals calculated would contain the true effect.
NOT: There is a 95% probability the true value is in this CI (frequentist interpretation).
Relationship Between CI and P-Value
CI and Significance Connection
For 95% CI: If the confidence interval excludes the null value (0 for differences, 1 for ratios), the result is statistically significant at p less than 0.05.
For 99% CI: Corresponds to p less than 0.01 threshold.
For 90% CI: Corresponds to p less than 0.10 threshold.
CI Components
Confidence Interval Interpretation
| CI Component | Meaning | Example (Mean Difference) | Interpretation |
|---|---|---|---|
| Point Estimate | Best guess of true effect | Mean difference = 8 points | Observed effect in this sample |
| Lower Bound | Minimum plausible effect | 95% CI: 2 to 14 points | True effect unlikely below 2 |
| Upper Bound | Maximum plausible effect | 95% CI: 2 to 14 points | True effect unlikely above 14 |
| Width | Precision of estimate | Width = 12 points (14 minus 2) | Wider = less precise, needs larger sample |
Clinical Application
Statistical vs Clinical Significance
Four Possible Scenarios:
Statistical and Clinical Significance Matrix
| Scenario | Statistical Significance | Clinical Significance | Interpretation |
|---|---|---|---|
| Ideal | p less than 0.05, CI excludes 0 | Effect exceeds MCID | Significant AND clinically meaningful - implement |
| Large Sample Problem | p less than 0.05, CI excludes 0 | Effect below MCID | Significant but trivial - do NOT implement |
| Underpowered Study | p greater than 0.05, CI includes 0 | Point estimate exceeds MCID | Not significant but trend - need larger study |
| True Null | p greater than 0.05, CI includes 0 | Effect well below MCID | No effect - do not implement |
Key Principle: Always check if effect size (point estimate) and CI bounds exceed MCID, not just if p less than 0.05.
Worked Example: THA Study
Study: Compares cemented vs uncemented THA on WOMAC score at 1 year.
Results:
- Mean difference = 8 points (cemented better)
- 95% CI: 1 to 15 points
- p = 0.02
- MCID for WOMAC = 10 points
Interpretation:
- Statistically Significant: p = 0.02 less than 0.05, CI excludes 0 → Yes
- Point Estimate: 8 points less than MCID of 10 → Not clinically meaningful
- CI Upper Bound: 15 points greater than MCID → Could be meaningful
- CI Lower Bound: 1 point much less than MCID → Could be trivial
Conclusion: Result is statistically significant but clinically uncertain. The CI is wide and crosses the MCID threshold. Point estimate suggests effect may not be clinically important. Need larger study to narrow CI and determine if true effect exceeds 10 points.
Understanding this nuanced interpretation prevents overconfidence in borderline results.
Commonly Confused Concepts (Differential)
Examiners frequently probe whether candidates can distinguish closely related statistical terms. The table below contrasts the concepts most often confused in vivas and the literature.
Distinguishing Commonly Confused Statistical Concepts
| Concept | What It Is | What It Is Often Confused With | Key Discriminator |
|---|---|---|---|
| P-value | Probability of data this extreme IF null is true | Probability the null is true | Conditional direction: P(data | H0), not P(H0 | data) |
| Alpha (significance level) | Pre-set acceptable Type I error rate | The observed p-value | Alpha is fixed before the study; p is computed from the data |
| Confidence interval | Plausible range for the true effect (frequentist) | Credible interval (Bayesian probability range) | Only a credible interval gives a direct probability for the parameter |
| Statistical significance | Effect unlikely under the null (p less than alpha) | Clinical significance | Clinical significance needs the effect to exceed the MCID |
| Type I error | False positive: rejecting a true null | Type II error (false negative) | Type I is alpha; Type II is beta (1 minus power) |
| Standard deviation | Spread of individual observations | Standard error (spread of the mean estimate) | SE = SD / sqrt(n); SE shrinks with larger samples, SD does not |
Controversies and Areas of Uncertainty
Statistical inference is an area of genuine, ongoing debate. Candidates who can articulate the controversy (not just recite rules) demonstrate consultant-level understanding.
Redefine vs Abandon Significance
Some authors propose lowering the threshold for new discoveries to p less than 0.005 to reduce false positives, while others argue for abandoning fixed thresholds entirely and reporting p-values as continuous evidence. No global consensus exists.
The p = 0.05 Convention
The 0.05 cut-off is a historical convention attributed to Fisher, not a scientific constant. Treating 0.049 and 0.051 as categorically different is statistically indefensible, yet remains common in practice and journal decisions.
Frequentist vs Bayesian
Frequentist CIs and p-values dominate orthopaedic literature, but Bayesian methods (credible intervals, Bayes factors) give the direct probability statements clinicians intuitively want. Adoption is growing but uneven.
Statistical vs Clinical Endpoints
There is no universally agreed MCID for many orthopaedic PROMs, and anchor-based versus distribution-based methods can give different values for the same instrument, complicating the judgement of clinical importance.
The Reproducibility Crisis Context
Concern over irreproducible findings across biomedical science has been driven substantially by the misuse of p-values: p-hacking (analysing data many ways until p less than 0.05), selective reporting, and underpowered studies. The exam-relevant lesson is that a single significant p-value, especially from a small or post-hoc analysis, is weak evidence until replicated and judged against effect size and prior plausibility.
Evidence Base
ASA Statement on Statistical Significance and P-Values
- P-values can indicate how incompatible data are with a specified statistical model, but do NOT measure the probability that the studied hypothesis is true
- Scientific conclusions should NOT be based only on whether a p-value passes a specific threshold such as 0.05
- A p-value does NOT measure the size or importance of an effect, nor provide a good measure of evidence on its own
- Proper inference requires full reporting and transparency, plus effect sizes and confidence intervals
Confidence Intervals Rather Than P Values: Estimation Rather Than Hypothesis Testing
- Overemphasis on hypothesis testing and dichotomising results as significant or non-significant detracts from more useful estimation approaches
- Investigators are usually interested in the SIZE of the difference between groups, not merely whether it is statistically significant
- Confidence intervals present a plausible range for the population value and convey magnitude, direction, and precision
- CIs should be reported for major findings in both the main text and the abstract
A Dirty Dozen: Twelve P-Value Misconceptions
- Reviews twelve common p-value misconceptions and explains why each is wrong, e.g. treating p as the probability the null is true
- The p-value is a measure of evidence that is not part of any formal system of statistical inference, making its meaning easily misconstrued
- Contrasts the p-value with the Bayes factor, which has interpretability properties the p-value lacks
- The most serious error is believing the probability of a wrong conclusion can be calculated from a single experiment without external evidence
Statistical Tests, P Values, Confidence Intervals, and Power: A Guide to Misinterpretations
- Provides an explanatory list of 25 distinct misinterpretations of p-values, confidence intervals, and statistical power
- Selective analysis (choosing what to present based on the p-value obtained) can produce small p-values even when the test hypothesis is correct
- There is no interpretation of these concepts that is simultaneously simple, intuitive, correct, and foolproof
- Concludes with practical guidelines for improving statistical interpretation and reporting
Guidelines, Registries & Global Practice
Reporting Standards Across the Global Literature
Statistical reporting expectations are remarkably consistent worldwide because they are driven by international journal and methodology guidelines rather than national bodies. The candidate should know which guideline governs which study type.
Major Reporting Guidelines Relevant to P-Values and CIs
| Guideline / Body | Scope | Position on P-Values and CIs |
|---|---|---|
| ASA (American Statistical Association, 2016) | Global statistical practice | Do not base conclusions on a single p threshold; report effect sizes and CIs |
| ICMJE (international journal editors) | All biomedical manuscripts | Quantify findings with appropriate indicators of measurement error such as confidence intervals; avoid relying solely on hypothesis testing |
| CONSORT (randomised trials) | RCT reporting | Report effect size and its precision (e.g. 95% CI) for primary and secondary outcomes |
| STROBE (observational studies) | Cohort, case-control, cross-sectional | Give estimates with confidence intervals; report so as not to over-interpret p-values |
| GRADE (evidence synthesis) | Guidelines and meta-analyses | Judges imprecision largely by CI width relative to clinical decision thresholds (MCID) |
Registries and Effect Estimation
Large national arthroplasty registries (NJR for England, Wales, Northern Ireland and the Isle of Man; AOANJRR Australia; SHAR Sweden; the Norwegian and New Zealand registries; AJRR USA) illustrate the practical primacy of confidence intervals over p-values. Because registry sample sizes run into hundreds of thousands, almost any difference reaches statistical significance. Registries therefore report hazard ratios and revision rates with narrow confidence intervals and interpret them against clinically meaningful thresholds, not against p = 0.05. This is the real-world embodiment of the large-sample problem: with very large n, statistical significance is near-guaranteed and effect size plus CI width become the only meaningful discriminators.
High- vs Limited-Resource Practice Variation
- Well-resourced settings: Routine access to statistical software and biostatistician support; journals enforce CI reporting and pre-registration, reducing selective p-value reporting.
- Limited-resource settings: Smaller single-centre studies predominate, raising the risk of underpowered analyses and Type II errors; wide confidence intervals are common and should be interpreted as inconclusive rather than negative.
- Universal principle: The interpretation of p-values and CIs does not change by country; what varies is study size, access to methodological support, and exposure to publication and reporting bias.
Global Exam Framing
Whichever fellowship you sit (FRCS, FRACS, EBOT, ABOS, DNB/MS, MRCS, SICOT), the expected answer is identical: interpret the confidence interval against the MCID, never equate statistical with clinical significance, and treat the p-value as one continuous piece of evidence, not a verdict.
Exam Viva Scenarios
Use these scenarios to practise clinical reasoning and management decisions
Scenario 1: P-Value Interpretation
"A colleague shows you an RCT comparing two rehab protocols. The study found no significant difference (p = 0.08). She concludes the protocols are equivalent. How do you respond?"
Scenario 2: Statistical vs Clinical Significance
"An RCT of 1000 patients found statistically significant improvement in WOMAC score with new treatment: mean difference = 3 points, 95% CI 1 to 5 points, p = 0.003. The MCID for WOMAC is 10 points. How do you interpret this?"
Scenario 3: Multiple Comparisons and Subgroups
"A trial of a new fixation device reported no overall difference, but the authors highlight that in the subgroup of smokers aged over 65 the device was significantly better (p = 0.04). The company asks you to adopt the device for this subgroup. How do you respond?"
MCQ Practice Points
P-Value Definition
Q: What does a p-value of 0.04 mean? A: Assuming null hypothesis is true, there is 4% probability of observing data this extreme or more extreme by chance alone. It does NOT mean 4% probability null is true, nor 4% probability of Type I error, nor 4% effect size.
CI and Significance
Q: A 95% CI for mean difference is -2 to 8 points. Is this statistically significant at alpha = 0.05? A: No - the CI includes 0 (no difference), meaning the result is NOT statistically significant. If CI excluded 0, p would be less than 0.05.
Statistical vs Clinical Significance
Q: Can a result be statistically significant but not clinically significant? A: Yes - large studies can detect tiny differences with p less than 0.05 that are below the MCID threshold. Statistical significance depends on sample size; clinical significance depends on whether effect exceeds MCID.
CI Width and Sample Size
Q: What does a wide confidence interval indicate? A: Imprecise estimate due to small sample size or high variability. A wide CI crossing both clinically important and trivial effects means the study is inconclusive - you cannot determine if the true effect is meaningful or not. This indicates the study is underpowered and needs a larger sample.
P-Value and Type I Error
Q: If p = 0.03, what is the probability this result is a false positive (Type I error)? A: Unknown - cannot be determined from p-value alone. Alpha (0.05) is the Type I error rate set BEFORE the study. The p-value (0.03) is calculated FROM the data. Many students confuse these - p-value is NOT the probability of Type I error for THIS specific result.
Non-Significant Results
Q: Study shows no significant difference (p = 0.15) between two treatments. Can you conclude the treatments are equally effective? A: No - failure to reject null does NOT prove null is true. This could be: (1) True null (treatments truly equivalent), OR (2) Type II error (underpowered study missing a real difference). Check the power calculation - if power is below 80%, cannot trust negative result. To prove equivalence, need a specifically designed equivalence or non-inferiority trial.
Management Algorithm
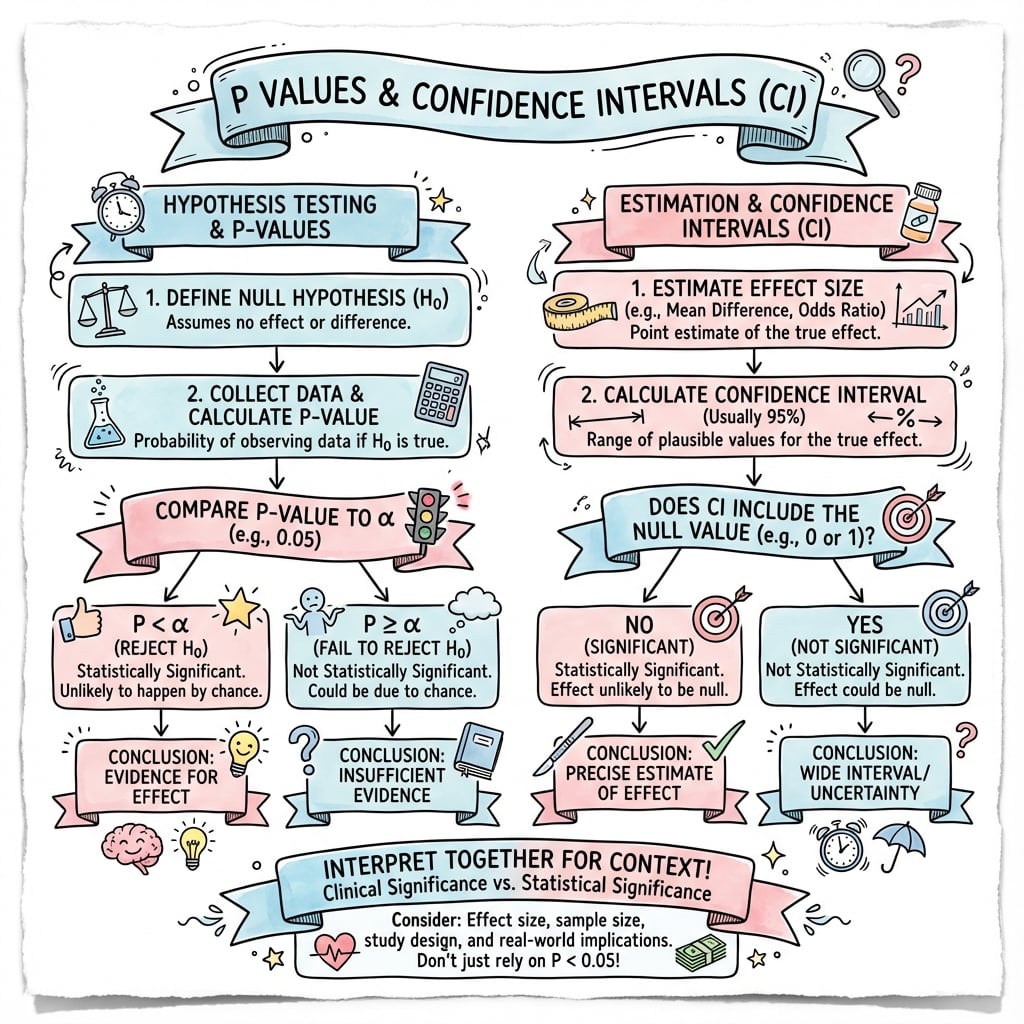
P-VALUES AND CONFIDENCE INTERVALS
Clinical summary
P-Value Interpretation
- •p-value = P(Data | Null is true), NOT P(Null is true | Data)
- •p less than 0.05 = statistically significant (arbitrary convention)
- •p-value does NOT indicate effect size or clinical importance
- •Large sample can yield p less than 0.05 for trivial effects
- •p greater than 0.05 does NOT prove null hypothesis (may be underpowered)
Confidence Interval Interpretation
- •95% CI = range of plausible values for true effect
- •If 95% CI excludes null (0 or 1), p less than 0.05
- •Narrow CI = precise estimate; Wide CI = imprecise, underpowered
- •CI provides effect size, precision, AND significance
- •Check if entire CI exceeds MCID for clinical relevance
Statistical vs Clinical Significance
- •Statistical significance = p less than 0.05, CI excludes null
- •Clinical significance = effect exceeds MCID
- •Can have statistical significance without clinical importance (large sample, trivial effect)
- •Can have clinical importance without statistical significance (small sample, large effect)
- •Always compare point estimate AND CI to MCID
Common Misconceptions
- •p-value is NOT probability null is true
- •p-value is NOT Type I error for this study (that is alpha)
- •p greater than 0.05 does NOT prove equivalence (may be Type II error)
- •0.05 threshold is arbitrary, not magic cutoff
- •CI contains more information than p-value alone
Clinical Application
- •Report effect sizes and CIs, not just p-values
- •Check if CI crosses MCID threshold for clinical uncertainty
- •Wide CI suggests need for larger study
- •Borderline p (0.05-0.10) may indicate trend, check power
- •Non-inferiority trials prove equivalence; superiority trials do not