Kappa, ICC and Bland-Altman
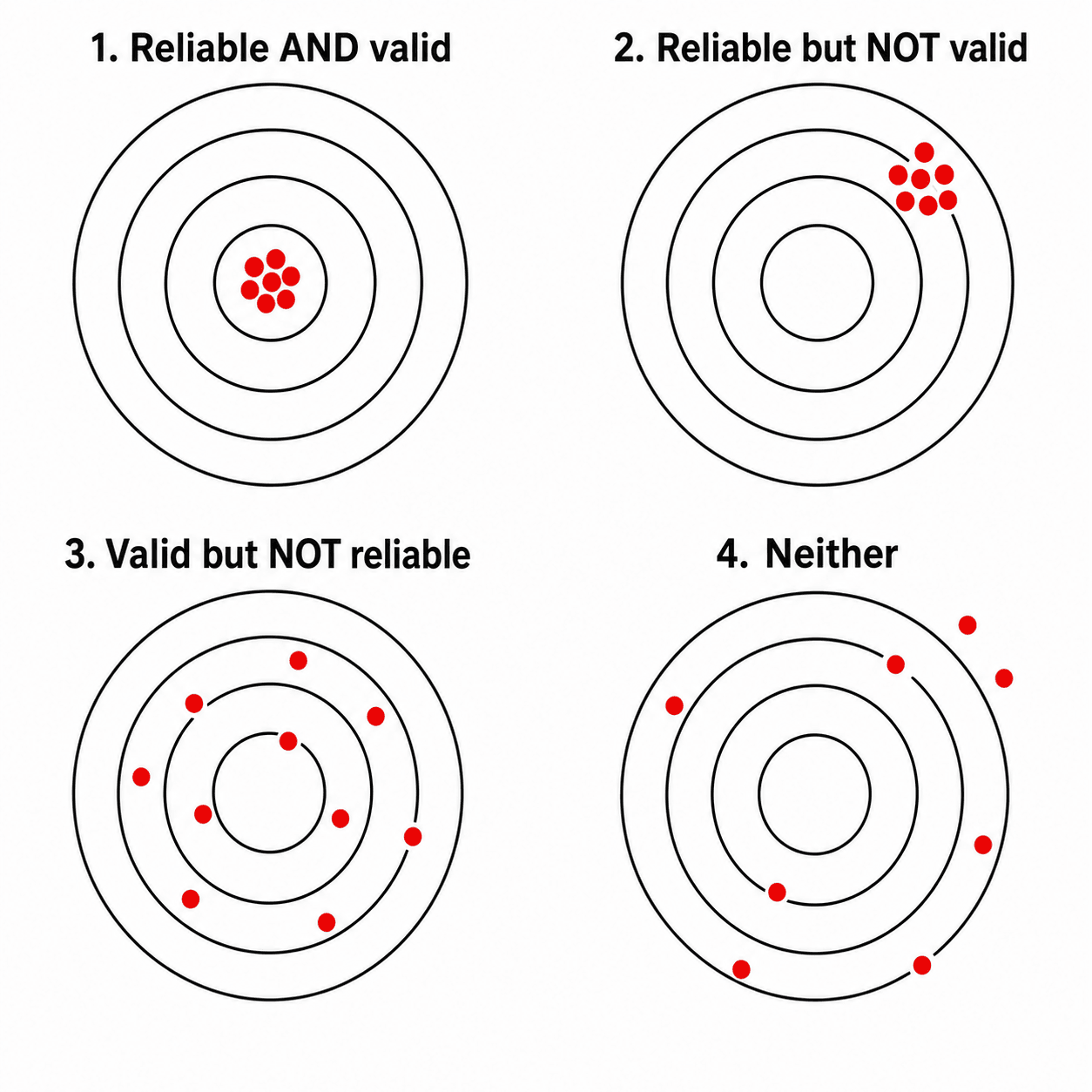
- RELIABILITY is reproducibility or PRECISION - how consistently a measurement gives the same result; VALIDITY is ACCURACY - whether it measures what it is supposed to. They are independent: a measurement can be RELIABLE WITHOUT being VALID (consistently wrong, a systematic bias), so reliability is necessary but NOT sufficient for validity (the dartboard analogy - tight grouping vs hitting the bullseye).
- Reliability has forms: INTRA-OBSERVER (the same rater repeating a measurement), INTER-OBSERVER (different raters), and TEST-RETEST (the same instrument over time); orthopaedic classification systems and outcome measures must be tested for these.
- For CATEGORICAL data (e.g. a fracture classification), agreement is measured by COHEN'S KAPPA between two raters - which corrects for the agreement expected by CHANCE - with FLEISS' kappa for more than two raters and WEIGHTED kappa for ORDINAL categories; the conventional LANDIS-KOCH interpretation is: below 0.20 slight, 0.21-0.40 fair, 0.41-0.60 moderate, 0.61-0.80 substantial, and 0.81-1.00 almost perfect agreement.
- For CONTINUOUS data (e.g. an angle or a length measurement), reliability is measured by the INTRACLASS CORRELATION COEFFICIENT (ICC), which runs from 0 to 1 (broadly above 0.75 is good and above 0.9 excellent), and method comparison is best shown with a BLAND-ALTMAN PLOT, which plots the DIFFERENCE between two methods against their MEAN to reveal systematic BIAS and the LIMITS OF AGREEMENT (mean difference +/- 1.96 standard deviations).
- A key trap is that CORRELATION (e.g. Pearson's r) is NOT agreement: two methods can correlate almost perfectly yet disagree systematically (one always reads higher), so r should NOT be used to claim two methods/raters agree - use the ICC or a Bland-Altman plot instead.
- Applied to orthopaedics: classification systems are valuable as a SHARED LANGUAGE but have LIMITED stand-alone reliability - increasing the number of categories/subcategories consistently REDUCES kappa/ICC, while a brief rater CALIBRATION session improves agreement; report agreement statistics with confidence intervals and choose the statistic that matches the data type.
- “Reliability = precision (reproducible); Validity = accuracy (true). Reliable can be invalid (systematic bias) - dartboard analogy.
- “Categorical agreement = kappa (Cohen's 2 raters, Fleiss' for more than 2, weighted for ordinal); Landis-Koch: 0.21-0.40 fair, 0.41-0.60 moderate, 0.61-0.80 substantial, 0.81-1.0 almost perfect.
- “Continuous: ICC for reliability; Bland-Altman (difference vs mean; bias + limits of agreement) for method comparison. Correlation is NOT agreement. More categories -> lower kappa.
Consistent, reproducible results. A reliable but invalid measure is consistently wrong (tight cluster, off the bullseye - systematic bias).
Measures the true value. Reliability is necessary but not sufficient for validity - you need both to hit the bullseye.
Reliability vs Validity
Reliability (reproducibility, precision) asks whether repeated measurements agree with each other; validity (accuracy) asks whether the measurement reflects the true value. The classic dartboard analogy makes the relationship clear: tight grouping = reliable, hitting the centre = valid. A measurement can be reliable but not valid - tightly clustered but systematically off-target (a bias) - so reliability is necessary but not sufficient for validity. Reliability comes in forms - intra-observer (same rater repeated), inter-observer (different raters) and test-retest (over time) - all of which matter when validating a classification system or an outcome measure.
Agreement Statistics
- Categorical data (e.g. a fracture classification): Cohen's KAPPA for two raters (corrects for chance agreement), Fleiss' kappa for more than two raters, and weighted kappa for ordinal categories. Interpret with Landis-Koch: below 0.20 slight, 0.21-0.40 fair, 0.41-0.60 moderate, 0.61-0.80 substantial, 0.81-1.00 almost perfect.
- Continuous data (e.g. angle/length measurements): the INTRACLASS CORRELATION COEFFICIENT (ICC) (0-1; broadly above 0.75 good, above 0.9 excellent) for reliability.
- Method comparison: the BLAND-ALTMAN plot - plot the difference between two methods against their mean, revealing systematic bias (the mean difference) and the limits of agreement (mean difference plus or minus 1.96 standard deviations).
- Do NOT use correlation (Pearson's r) to claim agreement - two methods can correlate strongly yet disagree systematically; use ICC or Bland-Altman.
| Data type / question | Statistic | Notes |
|---|
Validity Types & Classification Reliability
Validity has several forms: face (does it look reasonable), content (does it cover the construct), construct (does it behave as theory predicts), and criterion validity - concurrent (agrees with a gold standard now) and predictive (predicts a future outcome); sensitivity/specificity against a gold standard are criterion validity (see our Diagnostic Test Statistics topic). In orthopaedics, classification systems (e.g. fracture classifications) are tested for inter- and intra-observer reliability using kappa/ ICC; the evidence shows their stand-alone reliability is often only fair-to-moderate, that increasing granularity (more categories) lowers kappa/ICC, and that rater calibration improves agreement - which is why classifications are best used as a shared language and research scaffold alongside specific radiographic thresholds and patient factors, rather than as the sole basis for decisions.
Evidence & Key Studies
Distal radius fracture classifications in real life: reliability and how they change treatment
- Interobserver agreement for distal radius fracture classifications was typically fair-to-moderate on radiographs, with only modest improvement on CT.
- Increasing granularity (more categories/subcategories) consistently REDUCED kappa/ICC, whereas a brief rater calibration session improved agreement.
- Classifications remain valuable as a shared language but have limited stand-alone reliability and prognostic power, best combined with instability thresholds and patient factors.
Zero echo time MRI vs CT in intra-articular distal radius fractures: inter/intraobserver agreement
- Inter- and intraobserver agreement were quantified with Cohen's and Fleiss' kappa and intraclass correlation coefficients.
- Classification agreement was 'good' (kappa about 0.68-0.78), with surgeons agreeing more than radiologists; continuous measures showed good ICC for angulation (about 0.76-0.86) but lower for inclination.
- Illustrates the practical use and interpretation of kappa (categorical) and ICC (continuous) for reliability.
According to PubMed, the fair-to-moderate reliability of fracture classifications, the reduction of kappa/ICC with greater granularity and the benefit of rater calibration come from the cited Nguyen review, and the worked use of Cohen's/Fleiss' kappa and ICC (with interpretive values) from the cited Kaymakoglu study. The reliability-versus-validity distinction, the Landis-Koch kappa grades, the ICC and the Bland-Altman method- comparison approach are standard, well-established statistical teaching. (See also our Diagnostic Test Statistics, Measures of Effect and Study Design topics.)
Clinical Decision Scenarios
Practise clinical reasoning and management decisions out loud
“What is the difference between reliability and validity, and which statistics would you use to assess the reliability of a fracture classification and of an angle measurement?”
“Why do more detailed (granular) classification systems tend to be less reliable, and how can agreement be improved?”
Mnemonics & Memory Aids
PRECISE vs TRUE
Hook:Reliability = PRECISE; Validity = TRUE; you need both.
KIB
Hook:KIB: Kappa (categorical), ICC (continuous), Bland-Altman (method comparison).
Concepts
- Reliability = precision/reproducibility; validity = accuracy
- Reliable can be invalid (systematic bias) - dartboard analogy
- Reliability forms: intra-observer, inter-observer, test-retest
Categorical agreement
- Cohen's kappa (2 raters), Fleiss' kappa (more than 2), weighted kappa (ordinal)
- Corrects for chance agreement
- Landis-Koch: 0.21-0.40 fair, 0.41-0.60 moderate, 0.61-0.80 substantial, 0.81-1.0 almost perfect
Continuous agreement
- ICC for reliability (0-1; above 0.75 good, above 0.9 excellent)
- Bland-Altman for method comparison (difference vs mean; bias + limits of agreement)
- Correlation (Pearson r) is NOT agreement
Validity & classifications
- Validity: face, content, construct, criterion (concurrent/predictive)
- More categories -> lower kappa; rater calibration improves agreement
- Classifications = shared language; report kappa/ICC with CIs