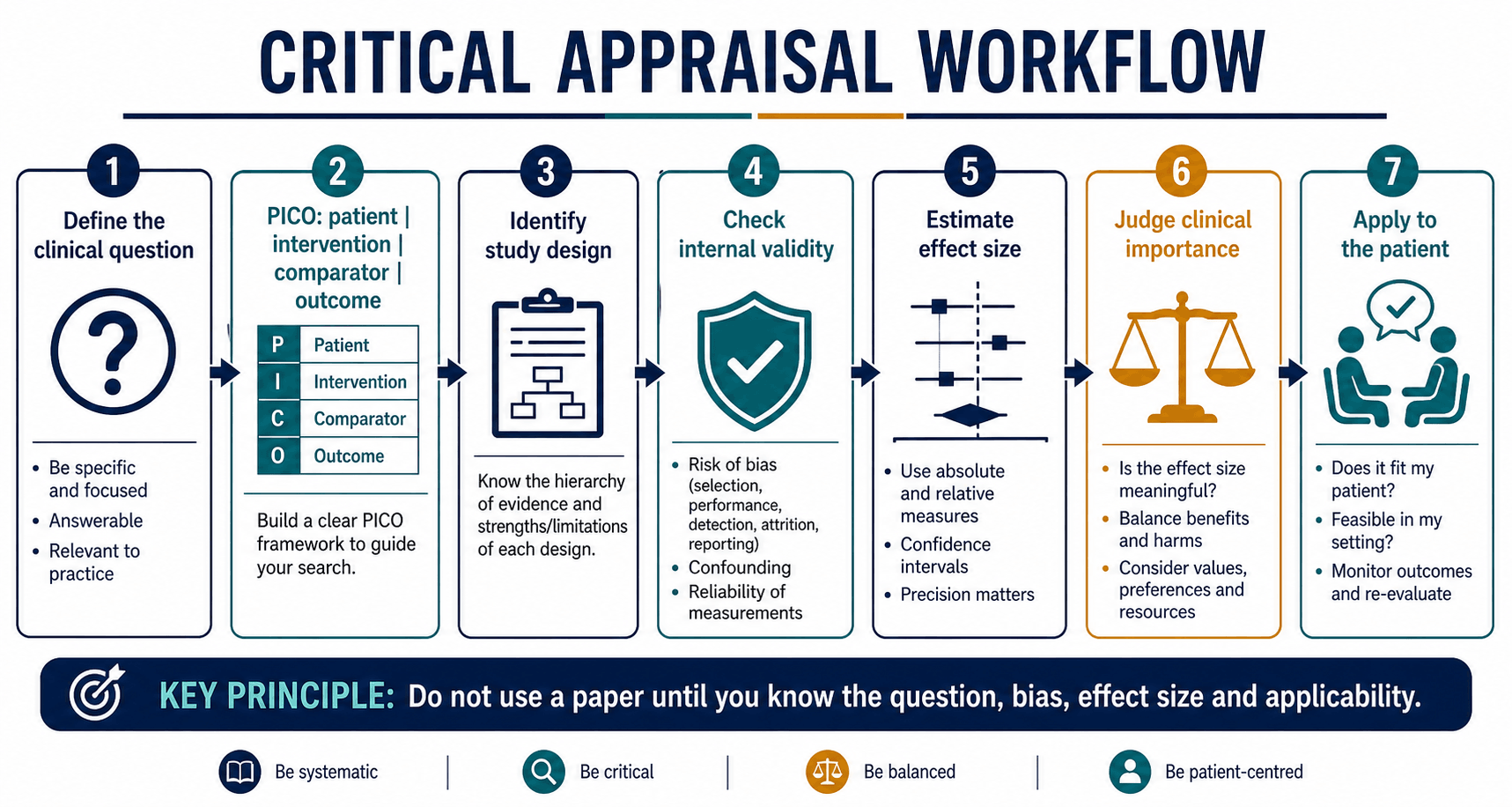
Question | validity | effect size | applicability
Appraisal Domains
Critical Must-Knows
- Critical appraisal is not a memory test of study designs. It is a structured judgement about whether a result should influence care.
- A randomised trial can still be unreliable. Poor allocation concealment, missing data, crossover and selective reporting can destroy credibility.
- A significant p value is not enough. Report effect size, absolute risk, confidence interval and clinical importance.
- Different questions need different designs. RCTs suit treatment efficacy; cohort studies suit prognosis; diagnostic studies need a reference standard.
- Evidence-based practice combines evidence, clinical expertise and patient values. It is not blind obedience to a paper.
Clinical Pearls
- "Start journal club by stating the PICO in one sentence.
- "Always separate internal validity from external applicability.
- "For binary outcomes, ask for absolute risk reduction and number needed to treat or harm.
- "A clinically trivial difference can be statistically significant in a large study.
- "A negative study may be underpowered rather than proof of no difference.
Do not confuse statistical significance with clinical importance
A p value answers whether the observed difference is compatible with chance under a statistical model. It does not tell you whether the effect is large enough to matter, whether harms are acceptable, or whether the result applies to your patient.
PAPERRead A Paper
| P | PICO Define the patient, intervention, comparator and outcome. |
| A | Appraise validity Look for bias before trusting the result. |
| P | Precision Read the confidence interval, not just the p value. |
| E | Effect size Translate relative and absolute effect into clinical terms. |
| R | Relevance Decide whether it applies to your patient and setting. |
| P | PICO Define the patient, intervention, comparator and outcome. | E | Effect size Translate relative and absolute effect into clinical terms. |
| A | Appraise validity Look for bias before trusting the result. | R | Relevance Decide whether it applies to your patient and setting. |
| P | Precision Read the confidence interval, not just the p value. |
Hook:Do not finish the PAPER until you know whether it should change practice.
BIASEDBias Screen
| B | Baseline balance Were groups similar at the start? |
| I | Intervention fidelity Were treatments delivered as intended? |
| A | Allocation concealment Could enrolment be predicted or manipulated? |
| S | Selective reporting Were all prespecified outcomes reported? |
| E | Endpoint blinding Were outcomes measured fairly? |
| D | Dropouts Was follow-up complete and balanced? |
| B | Baseline balance Were groups similar at the start? | A | Allocation concealment Could enrolment be predicted or manipulated? | E | Endpoint blinding Were outcomes measured fairly? |
| I | Intervention fidelity Were treatments delivered as intended? | S | Selective reporting Were all prespecified outcomes reported? | D | Dropouts Was follow-up complete and balanced? |
Hook:A BIASED paper can have a beautiful p value.
CARESApply Evidence
| C | Clinical importance Is the effect larger than a meaningful threshold? |
| A | Applicability Does the population match the patient? |
| R | Risks Balance complications, reoperation and downstream harm. |
| E | Expertise Can the technique be delivered safely in your system? |
| S | Shared decision Does the evidence fit the patient's values and goals? |
| C | Clinical importance Is the effect larger than a meaningful threshold? | E | Expertise Can the technique be delivered safely in your system? |
| A | Applicability Does the population match the patient? | S | Shared decision Does the evidence fit the patient's values and goals? |
| R | Risks Balance complications, reoperation and downstream harm. |
Hook:Evidence CARES only when it changes a real decision safely.
Overview
Evidence-based orthopaedics means using the best available research, clinical judgement and patient values to make decisions. It does not mean automatically following the newest paper, the biggest trial, the loudest conference presentation or the most quoted meta-analysis.
The practical question is always:
Can I Believe It?
This is internal validity. Ask whether the methods protected the result from bias, confounding, measurement error and missing data.
Should I Use It?
This is applicability. Ask whether the patient, intervention, comparator, outcome, surgeon skill and health system match your clinical decision.
The one-sentence appraisal opening
Begin by saying: "This paper asks whether intervention X compared with Y improves outcome Z in patients like this, and the key question is whether the methods and effect size are strong enough to change practice."
Concepts and Study Design
PICO before methods
PICO prevents vague appraisal. A paper about "fixation is better" is not appraisable until you define the patient, intervention, comparator and outcome.
PICO in Orthopaedics
| Element | Question | Example |
|---|---|---|
| Patient | Who exactly is being treated? | Older adults with displaced intracapsular femoral neck fracture who were ambulatory before injury. |
| Intervention | What is the treatment, implant or pathway? | Total hip arthroplasty through a specified approach. |
| Comparator | What is it being compared with? | Hemiarthroplasty, non-operative treatment, another implant or another rehabilitation pathway. |
| Outcome | What matters and when? | Reoperation, function, pain, dislocation, infection, mortality, revision, cost and patient-reported outcome at a defined time. |
Match study design to question
Treatment Questions
| Best Designs | What To Check | Orthopaedic Trap |
|---|---|---|
| Randomised trial or high-quality systematic review | Random sequence, allocation concealment, blinding where possible, intention-to-treat and follow-up. | Surgical trials may be hard to blind, so outcome assessment and crossover matter. |
| Registry or cohort study | Confounding control, selection bias, surgeon/implant learning curve and outcome definition. | Registry survival may not capture pain, function or radiographic failure. |
Clinical Relevance
Internal validity: can I believe the result?

Core Bias Checks
| Bias | Question To Ask | Orthopaedic Example |
|---|---|---|
| Selection bias | Were patients allocated or selected in a way that created unfair groups? | Healthier patients receive surgery while frailer patients receive non-operative care. |
| Performance bias | Were co-interventions and rehabilitation similar? | One ACL group receives more supervised physiotherapy than the other. |
| Detection bias | Were outcomes assessed fairly and blindly? | Surgeon-assessed radiographic union favours their preferred implant. |
| Attrition bias | Who was lost to follow-up? | Painful failures do not return to clinic and are counted as successes. |
| Confounding | What else explains the result? | High-volume surgeons use one implant and low-volume surgeons use another. |
| Reporting bias | Were all prespecified outcomes reported? | The published paper reports range of motion but omits reoperation. |
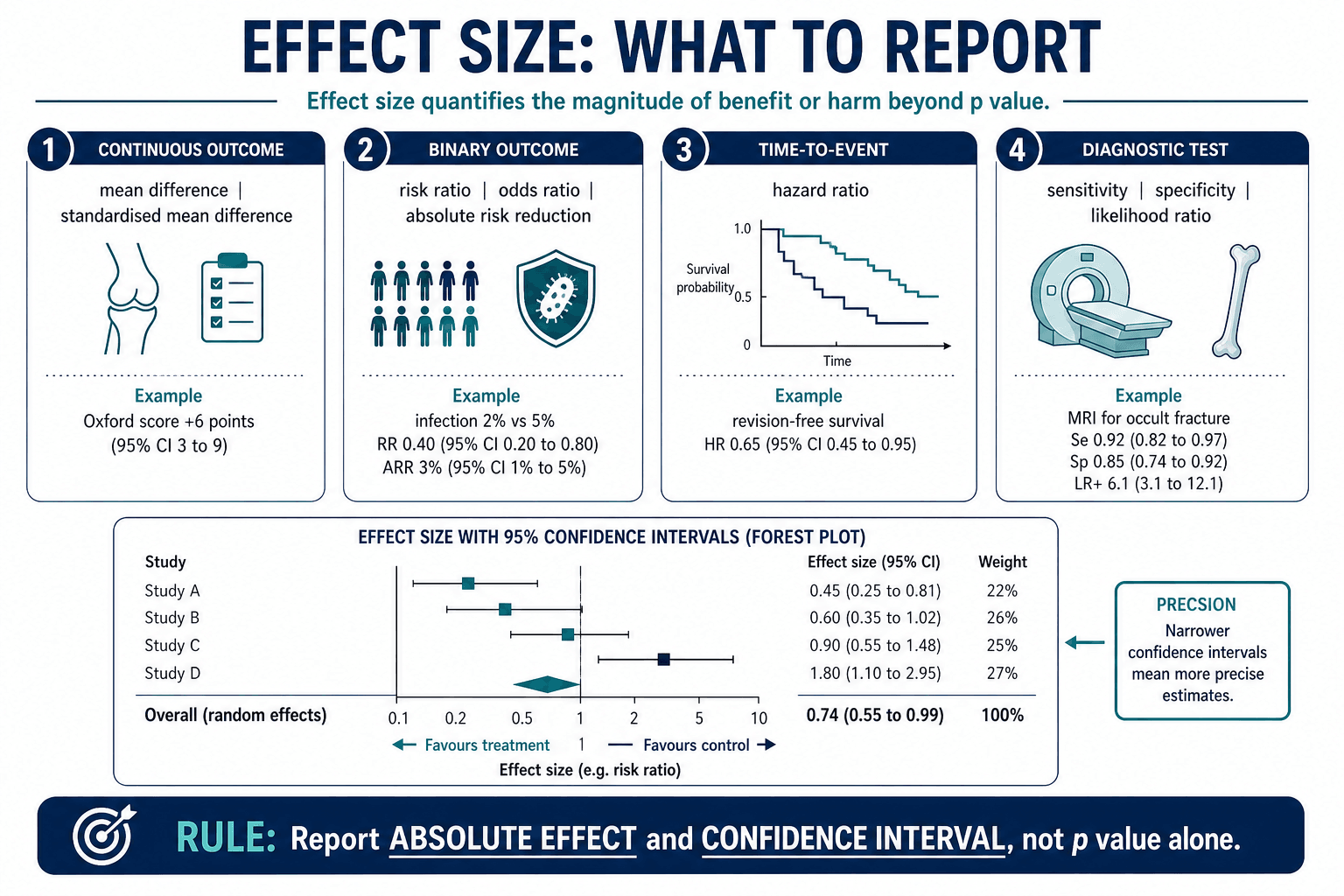
Effect size: what does the number mean?
Interpreting Common Results
| Reported Result | What To Translate | Decision Question |
|---|---|---|
| Mean difference | Difference in points, degrees, millimetres or time. | Is it greater than the minimum clinically important difference? |
| Risk ratio or odds ratio | Relative change plus absolute baseline risk. | How many events are actually prevented or caused? |
| Absolute risk reduction | Event rate difference between groups. | What is the number needed to treat or harm? |
| Hazard ratio | Relative event rate over time. | Are proportional hazards plausible and follow-up long enough? |
| Sensitivity and specificity | Test performance against reference standard. | How does the result change post-test probability? |
Applicability: should I use it?
A valid result still may not apply. Check:
- Patient match: age, frailty, bone quality, comorbidity, activity level and pathology severity.
- Intervention match: implant, surgical approach, rehabilitation protocol and perioperative care.
- Surgeon/system match: volume, learning curve, imaging access, theatre resources and follow-up capability.
- Outcome match: patient-reported outcomes, revision, reoperation, complications, cost and survivorship.
- Time horizon: short-term function may conflict with long-term revision risk.
Registry data and RCTs answer different questions
Registry studies often excel at large-scale implant survivorship and rare revision outcomes. Randomised trials better test efficacy in controlled populations. Neither replaces the other.
Differential: easily confused concepts
The commonest appraisal errors in vivas come from mixing up paired concepts that sound similar but answer different questions. Knowing the distinction is high yield.
Distinguishing Commonly Confused Appraisal Concepts
| Often Confused | What It Actually Means | Why It Matters |
|---|---|---|
| Statistical significance vs clinical importance | A p value tests compatibility with chance; clinical importance tests whether the effect exceeds a meaningful threshold. | A large trial can make a trivial difference significant; a small trial can miss an important one. |
| Relative vs absolute effect | Relative risk or odds ratio is a ratio; absolute risk reduction is the actual event-rate difference. | A halving of risk (relative) may be a fraction of a percent (absolute) when baseline risk is low. |
| Allocation concealment vs blinding | Concealment hides the upcoming assignment before enrolment; blinding hides the received treatment afterwards. | Concealment protects randomisation integrity; blinding protects performance and detection. |
| Confidence interval vs p value | A confidence interval shows the range of effects compatible with the data; the p value gives a single threshold answer. | A non-significant result with a wide interval is uncertainty, not proof of no effect. |
| Per-protocol vs intention-to-treat | Intention-to-treat keeps patients in their randomised group; per-protocol analyses only compliant patients. | Per-protocol can reintroduce selection bias and exaggerate surgical benefit. |
| Efficacy vs effectiveness | Efficacy is performance under ideal trial conditions; effectiveness is performance in routine practice. | A result from an expert centre may not transfer to a general unit (the efficacy-effectiveness gap). |
Controversies and Areas of Uncertainty
Critical appraisal is itself debated. Examiners reward candidates who can discuss the limits of the evidence hierarchy rather than reciting it.
Hierarchy vs real-world evidence
The classical pyramid places randomised trials above observational data, yet large registries and target-trial-emulation methods can answer questions (rare implant failure, long-term survivorship) that no feasible trial can. Many surgical questions cannot be ethically or practically randomised.
Surgical RCTs are hard
Blinding the surgeon is impossible, learning curves bias early results, equipoise is often lacking, and expertise-based designs are uncommon. A poorly conducted surgical trial may be weaker than a well-designed cohort study.
Reproducibility and reporting
Selective outcome reporting, spin in abstracts, underpowered studies and unregistered protocols remain common in the orthopaedic literature. Trial registration and core outcome sets are partial but incomplete remedies.
MCID is not fixed
The minimum clinically important difference varies by population, anchor method and baseline severity, so the same point change can be "important" in one study and not another. Treat any single MCID value with caution.
A mature appraisal answer
Say explicitly that the evidence hierarchy ranks designs on average but that a specific study must be judged on its own conduct, and that for many surgical questions high-quality observational and registry data are the best obtainable evidence.
Evidence Base
Evidence-based medicine definition
- Evidence-based medicine integrates best evidence with clinical expertise and patient values.
- It is not cookbook medicine.
- External evidence can inform but not replace clinical judgement.
GRADE approach
- GRADE separates certainty of evidence from strength of recommendation.
- Evidence can be downgraded for risk of bias, inconsistency, indirectness, imprecision and publication bias.
- Recommendations also depend on values, harms and resource use.
Reporting guidelines
- Different study types require different reporting checklists.
- Transparent reporting helps readers judge bias and applicability.
- Poor reporting does not always mean poor methods, but it prevents confident appraisal.
AMSTAR 2
- AMSTAR 2 provides a structured method for appraising systematic reviews of healthcare interventions.
- It distinguishes critical from non-critical weaknesses.
- A meta-analysis can be misleading if the review question, search, bias assessment or synthesis is weak.
Levels of evidence in orthopaedics
- Major orthopaedic journals adopted a five-level hierarchy (Level I randomised trials through Level V expert opinion) applied separately to therapeutic, prognostic, diagnostic and economic questions.
- The level assigned depends on both study design and methodological quality, so a flawed randomised trial can drop below Level I.
- The grading was introduced to help readers rapidly gauge the strength of orthopaedic evidence.
Large orthopaedic RCT as appraisal exemplar (SPRINT)
- A multicentre randomised trial enrolling 1200 skeletally mature patients across 29 sites in Canada, the United States and the Netherlands compared reamed with non-reamed intramedullary nailing of tibial shaft fractures.
- Patients, outcome assessors and data analysts were blinded, and a blinded committee adjudicated the composite reoperation primary outcome.
- An a priori subgroup analysis separated open from closed fractures, illustrating prespecified rather than data-driven subgrouping.
Clinical Scenarios
Use these scenarios to practise clinical reasoning and management decisions
"You are shown a randomised trial comparing two fixation methods. The conclusion says one implant is statistically superior with p = 0.04."
"A meta-analysis reports that a surgical technique reduces revision risk. The forest plot looks convincing, but the included studies are heterogeneous observational cohorts."
"A paper reports that a new clinical test for a meniscal tear has a sensitivity of 90 percent and a specificity of 60 percent, validated against arthroscopy in a specialist sports clinic."
Guidelines, Registries and Global Practice
Critical appraisal is the engine behind every guideline and registry, so candidates from any system should know how the major bodies build and grade recommendations and how their orthopaedic registries are used as evidence.
How major bodies grade evidence
Evidence-Grading Approaches Across Bodies
| Body | Approach | What To Note |
|---|---|---|
| AAOS (US) | Clinical practice guidelines using a structured strength-of-recommendation system from systematic reviews. | Recommendation strength reflects evidence quality plus consistency; many orthopaedic topics rest on limited or moderate evidence. |
| NICE and BOA/BOAST (UK) | NICE uses GRADE-based methods; BOAST standards translate evidence into auditable care standards. | BOAST documents convert evidence into concise, measurable practice points. |
| AO Foundation | Education and consensus around fracture management with evidence summaries. | Strong on technique and classification; consensus may outpace high-level trial data. |
| EFORT and European societies | Consensus statements and instructional reviews across Europe. | Useful where regional practice and implant availability differ. |
| Cochrane / GRADE working group | Systematic reviews with explicit GRADE certainty ratings. | Often rate orthopaedic surgical evidence as low or moderate certainty. |
Registries as evidence
National joint replacement registries are a defining global source of orthopaedic effectiveness and safety data. They capture rare revision events and long-term survivorship that trials cannot.
- AOANJRR (Australia), NJR (England, Wales, NI and Isle of Man), AJRR (US), SHAR (Sweden), NARA (Nordic) and NZJR (New Zealand) provide implant survivorship, revision rates and bearing or fixation comparisons across hundreds of thousands of procedures.
- Strengths: large numbers, real-world populations, early detection of poorly performing implants (the metal-on-metal hip signal is the classic example).
- Limitations: confounding by indication, limited patient-reported outcomes, variable capture of function and pain, and dependence on accurate data entry.
High-resource versus limited-resource practice
Applying Evidence Across Resource Settings
| Dimension | Higher-resource setting | Limited-resource setting |
|---|---|---|
| Access to evidence | Subscription journals, guideline databases and registries. | Reliance on open-access sources, WHO guidance and society summaries. |
| Applicability of trials | Populations often match trial cohorts. | Implant availability, follow-up capacity and case mix may differ from trial settings. |
| Outcome priorities | Revision, patient-reported outcomes and survivorship. | Limb salvage, infection control and return to function may dominate. |
Global framing
A guideline or registry finding from any one country is evidence contributing to a global picture; the appraisal question is always whether the population, implant and system match the patient in front of you, not which country produced the data.
Critical Appraisal Cheat Sheet
Clinical summary
Start
- •State the PICO
- •Identify study design
- •Ask if design matches question
- •Find primary outcome
- •Check follow-up duration
Believe
- •Selection bias
- •Allocation concealment
- •Blinding/outcome assessment
- •Missing data
- •Confounding and reporting bias
Use
- •Absolute and relative effect
- •Confidence interval
- •Clinical importance
- •Benefits versus harms
- •Applicability to patient and setting
"Define the question, test the validity, quantify the effect and decide whether it applies."